Everybody’s talking about CrewAI, so let me clarify a few things.
There are many frameworks and libraries out there that abstract away the complexities of orchestrating AI agents, where each agent is a specialist in their own right, working together to solve complex problems.
CrewAI is one of the latest frameworks that assists with this orchestration. It utilizes LangChain Agents but enhances them with role-playing and memory mechanisms.
Given LangChain’s ease of use, it opens up a world of applications. Once you dive into it, you’ll not only harness the power of existing LangChain tools but also contribute to the ecosystem by crafting tools tailored to your specific needs. I’ve always been a proponent of the flywheel effect — once you start, it only becomes easier and more powerful.
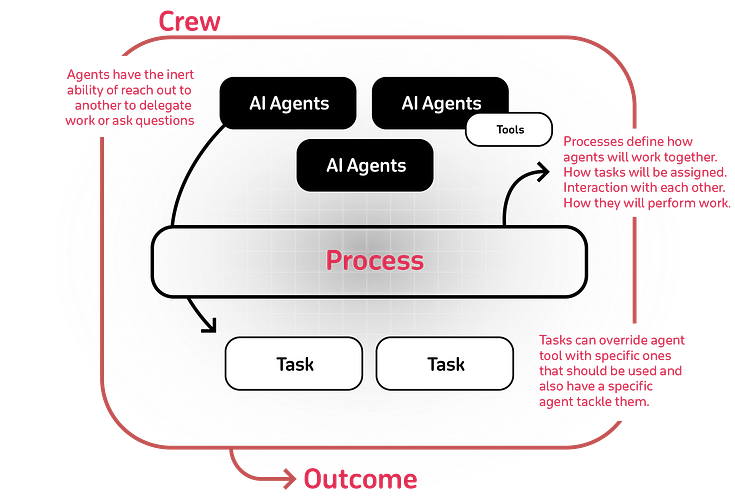
Model diversification is also crucial here. By integrating a mix of cloud-based and local models, or even fine-tuning your own models for specific agents, you can significantly enhance your crew’s capabilities.
And ‘sequential’ processes are just the beginning. The concept of ‘consensual’ and ‘hierarchical’ processes opens up a world of collaborative executions that I can’t wait to explore. Very soon, agents will be able to dynamically delegate subtasks to simulate a real-world work environment, making us more efficient and intelligent.
In this article, I’ll walk you through
- Local installation
- Creating a crew of agents
- Leveraging local LLMs
- Points to consider when working with orchestration frameworks
- Notable examples
Let’s go!
Getting Started with CrewAI
First, you need to setup an environment and install CrewAI.
Open your command line interface — this could be your Command Prompt, Terminal, or any other CLI tool you’re comfortable with. Make sure you have Python installed because we’re going to use pip, Python’s package installer. Now, type in the following commands:
<span id="d723" data-selectable-paragraph=""><br><span>mkdir</span> crewai-orchestration && <span>cd</span> crewai-orchestration<br>python3 -m venv crewai-orchestration-env<br><span>source</span> crewai-orchestration-env/bin/activate<br><br><br>pip3 install ipykernel jupyter<br>pip3 install python-dotenv<br>pip3 install crewai<br>pip3 install -U duckduckgo-search<br><br><br>code .</span>
OK, so we set up the environment, checked Python Package Index, find few packages and installed them along with all necessary dependencies.
Next, in your root directory, create .env file and add your OpenAI API Key:
<span id="9b38" data-selectable-paragraph=""><span>OPENAI_API_KEY</span>=<Your API Key></span>
Always good to treat your API keys like the access badge to a ultra secure building — it should be kept secret and not shared publicly.
To continue, you can either create .py file or .ipynb file (notebook). I will continue with Jupyter notebook to run code in blocks and interactively inspect the results.
Once you have your environment set up, it’s time to assemble a crew of agents.
Creating a Crew of Agents
We will now assemble a crew of agents. While we are doing that, think of these agents as modular components, each with a specific role in a larger system.
Let’s begin by importing the required modules.
<span id="c2d8" data-selectable-paragraph=""><span>import</span> os<br><span>from</span> crewai <span>import</span> Agent, Task, Process, Crew<br><br><span>from</span> dotenv <span>import</span> load_dotenv <br><br>load_dotenv()<br><br><br><span>import</span> logging<br>logging.basicConfig(level=logging.INFO)</span>
In this example, we’ll use DuckDuckGo to search the web. However, CrewAI is flexible, and you can choose from a variety of tools.
<span id="63cd" data-selectable-paragraph="">from langchain.tools <span>import</span> <span>DuckDuckGoSearchRun</span><br><span>search_tool</span> <span>=</span> DuckDuckGoSearchRun()</span>
Now, agents have everything they need to browse the internet and collect information.
Bring in the Agents
It’s time to introduce the agents with their specific roles and goals.
Here’s how you define them:
<span id="eff9" data-selectable-paragraph="">researcher = Agent(<br> role=<span>'Senior Research Analyst'</span>,<br> goal=<span>'Find out details regarding Gradient Descent'</span>,<br> backstory=<span>"""You are an expert in deep learning. <br> You are passionate about education.<br> You can explain complex concepts into simple terms."""</span>,<br> verbose=<span>True</span>,<br> allow_delegation=<span>False</span>,<br> tools=[search_tool]<br> <br> <br> <br> <br> <br> <br> <br>)<br><br>writer = Agent(<br> role=<span>'Technical Writer'</span>,<br> goal=<span>'Craft compelling content on Gradient Descent'</span>,<br> backstory=<span>"""You are a renowned Technical Writer, known for<br> your informative and insightful articles.<br> You transform complex concepts into compelling narratives."""</span>,<br> verbose=<span>True</span>,<br> allow_delegation=<span>True</span>,<br> <br>)</span>
Create as many agents as you need, each with their unique role, goal, and backstory.
Assigning the Tasks
With your agents ready, you can now define their tasks.
Each task should be clear and concise:
<span id="6235" data-selectable-paragraph=""><br>task1 = Task(<br> description=<span>"""Conduct a comprehensive analysis of Gradient Descent.<br> Identify key definitions and potential use-cases.<br> Your final answer MUST be a full analysis"""</span>,<br> agent=researcher<br>)<br><br>task2 = Task(<br> description=<span>"""Using the insights provided, develop an technical blog<br> post that highlights the most important aspects of Gradient Descent.<br> Your post should be informative yet accessible, catering to a tech-savvy audience.<br> Your final answer MUST be the full blog post of at least 4 paragraphs."""</span>,<br> agent=writer<br>)</span>
Assemble the Crew
Now, gather your agents into a crew and set the process type, which determines how they will work together:
<span id="8278" data-selectable-paragraph=""><br>crew = Crew(<br> agents=[researcher, writer],<br> tasks=[task1, task2],<br> verbose=<span>2</span>, <br>)</span>
Kick Things Off
Finally, it’s showtime! Run the crew and wait for the outcome:
<span id="4269" data-selectable-paragraph="">result = crew.kickoff()<br><span>print</span>(result)</span>
<span id="c2d1" data-selectable-paragraph=""><br>[DEBUG]: Working Agent: Senior Research Analyst<br><br>[INFO]: Starting Task: Conduct a comprehensive analysis of Gradient Descent.<br> Identify key definitions and potential use-cases.<br> Your final answer MUST be a full analysis<br><br><br>[1m> Entering new CrewAgentExecutor chain...[0m<br>INFO:httpx:HTTP Request: POST https://api.openai.com/v1/chat/completions "HTTP/1.1 200 OK"<br>[32;1m[1;3mThought: Do I need to use a tool? No<br><br>Final Answer: Gradient Descent is a first-order optimization algorithm used primarily for minimizing cost functions in machine learning and artificial intelligence models. It's a way to find the minimum of a function. <br><br>Let's break it down further:<br><br>- Gradient: In simple terms, the gradient measures the rate at which the output of a function is changing at each point. It's a vector that points in the direction of the greatest rate of increase of the function, and its magnitude is the rate of that increase.<br><br>- Descent: This suggests that we are trying to "descend" to the bottom of a function, i.e., find where it reaches its minimum value.<br><br>How It Works:<br><br>1. We start with a random point on the function and move in the negative direction of the gradient of the function to reach the local/global minimum.<br><br>2. A learning rate is used to limit the amount we move in the direction of the gradient. This is important because the update rule involves subtracting the product of learning rate and gradient from the current weights (parameters) of the function. If the learning rate is too high, we can overshoot the optimal point. If it is too low, then the algorithm will be too slow.<br><br>3. The process is repeated iteratively until the algorithm converges to the minimum point.<br><br>Use Cases:<br><br>Gradient Descent is used in training almost all the machine learning models, including but not limited to:<br><br>- Linear Regression<br>- Logistic Regression<br>- Neural Networks<br>- Support Vector Machines<br><br>There are three types of Gradient Descent algorithms:<br><br>1. Batch Gradient Descent: It uses all the data points in the training set for each update. This can be computationally expensive for large datasets.<br><br>2. Stochastic Gradient Descent (SGD): It uses only a single data point or a random data point from the training set for each update, which makes it much faster and able to deal with larger datasets.<br><br>3. Mini-Batch Gradient Descent: A compromise between Batch and Stochastic GD, it uses a mini-batch of n data points for each update, which can provide a balance between computational efficiency and convergence speed.<br><br>Limitations:<br><br>- It might get stuck in local minima in case of non-convex error surfaces.<br>- It can be sensitive to the initial point or learning rate.<br>- It doesn't work well when feature scales are different.<br><br>Despite these limitations, Gradient Descent is a fundamental concept in machine learning and is used in the training of many types of models. It is also a stepping stone to understanding more complex optimization algorithms.[0m<br><br>[1m> Finished chain.[0m<br>INFO:httpx:HTTP Request: POST https://api.openai.com/v1/chat/completions "HTTP/1.1 200 OK"<br><br>[DEBUG]: [Senior Research Analyst] Task output: Gradient Descent is a first-order optimization algorithm used primarily for minimizing cost functions in machine learning and artificial intelligence models. It's a way to find the minimum of a function. <br><br>Let's break it down further:<br><br>- Gradient: In simple terms, the gradient measures the rate at which the output of a function is changing at each point. It's a vector that points in the direction of the greatest rate of increase of the function, and its magnitude is the rate of that increase.<br><br>- Descent: This suggests that we are trying to "descend" to the bottom of a function, i.e., find where it reaches its minimum value.<br><br>How It Works:<br><br>1. We start with a random point on the function and move in the negative direction of the gradient of the function to reach the local/global minimum.<br><br>2. A learning rate is used to limit the amount we move in the direction of the gradient. This is important because the update rule involves subtracting the product of learning rate and gradient from the current weights (parameters) of the function. If the learning rate is too high, we can overshoot the optimal point. If it is too low, then the algorithm will be too slow.<br><br>3. The process is repeated iteratively until the algorithm converges to the minimum point.<br><br>Use Cases:<br><br>Gradient Descent is used in training almost all the machine learning models, including but not limited to:<br><br>- Linear Regression<br>- Logistic Regression<br>- Neural Networks<br>- Support Vector Machines<br><br>There are three types of Gradient Descent algorithms:<br><br>1. Batch Gradient Descent: It uses all the data points in the training set for each update. This can be computationally expensive for large datasets.<br><br>2. Stochastic Gradient Descent (SGD): It uses only a single data point or a random data point from the training set for each update, which makes it much faster and able to deal with larger datasets.<br><br>3. Mini-Batch Gradient Descent: A compromise between Batch and Stochastic GD, it uses a mini-batch of n data points for each update, which can provide a balance between computational efficiency and convergence speed.<br><br>Limitations:<br><br>- It might get stuck in local minima in case of non-convex error surfaces.<br>- It can be sensitive to the initial point or learning rate.<br>- It doesn't work well when feature scales are different.<br><br>Despite these limitations, Gradient Descent is a fundamental concept in machine learning and is used in the training of many types of models. It is also a stepping stone to understanding more complex optimization algorithms.<br><br><br><br>[DEBUG]: Working Agent: Technical Writer<br><br>[INFO]: Starting Task: Using the insights provided, develop an technical blog<br> post that highlights the most important aspects of Gradient Descent.<br> Your post should be informative yet accessible, catering to a tech-savvy audience.<br> Your final answer MUST be the full blog post of at least 4 paragraphs.<br><br><br>[1m> Entering new CrewAgentExecutor chain...[0m<br>INFO:httpx:HTTP Request: POST https://api.openai.com/v1/chat/completions "HTTP/1.1 200 OK"<br>[32;1m[1;3mThought: Do I need to use a tool? No<br><br>Final Answer: <br><br>Title: "Conquering Complexity: A Dive into the Dynamics of Gradient Descent"<br><br>In the realm of machine learning and artificial intelligence, one algorithm stands out for its ubiquitous utility and elegant simplicity: Gradient Descent. A first-order optimization algorithm, Gradient Descent serves as a cornerstone for minimizing cost functions in our models. But what exactly is it and why is it so important?<br><br>Let's start by dissecting the name. 'Gradient', in the simplest terms, measures the rate at which the output of a function changes at each point. It's like a compass for our algorithm, pointing the direction of the greatest rate of increase. Then comes 'Descent', indicating our goal of reaching the minimum value of the function. Imagine standing on a hill and wanting to get to the bottom - Gradient Descent is the GPS that guides us there!<br><br>So, how does this GPS guide us? The process starts with a random point on the function. We then move in the direction opposite to the gradient, nudging us closer to the local or global minimum. Here's where the 'learning rate' comes in - it's the step size that we take towards the minimum. Think of it as the speed of our descent. Too high a speed, and we risk overshooting our destination. Too slow, and our journey becomes painfully long. The algorithm continues these steps until it converges to the minimum point. <br><br>The beauty of Gradient Descent lies in its wide application. From Linear Regression and Logistic Regression to Neural Networks and Support Vector Machines, this versatile algorithm is at the heart of training various machine learning models. Moreover, it comes in three flavors: Batch Gradient Descent (using all data points for each update), Stochastic Gradient Descent (utilizing a single, random data point for each update), and Mini-Batch Gradient Descent (employing a small set of data points for each update). Thus, depending on the size of the dataset and computational efficiency, we can select the best-suited variant.<br><br>However, every hero has its Achilles heel. Gradient Descent can sometimes get stuck in local minima for non-convex error surfaces or can be sensitive to the initial point or learning rate. It may also stumble when feature scales are different. But fret not! Despite these limitations, the importance of Gradient Descent in machine learning is undisputed. It continues to be a vital tool in our arsenal and a stepping stone to understanding more complex optimization algorithms. <br><br>In conclusion, understanding Gradient Descent is akin to unlocking a fundamental secret of the universe of machine learning. It not only equips us with a robust optimization tool but also lays a solid foundation for grasping more advanced concepts in this fascinating field.[0m<br><br>[1m> Finished chain.[0m<br>INFO:httpx:HTTP Request: POST https://api.openai.com/v1/chat/completions "HTTP/1.1 200 OK"<br><br>[DEBUG]: [Technical Writer] Task output: Title: "Conquering Complexity: A Dive into the Dynamics of Gradient Descent"<br><br>In the realm of machine learning and artificial intelligence, one algorithm stands out for its ubiquitous utility and elegant simplicity: Gradient Descent. A first-order optimization algorithm, Gradient Descent serves as a cornerstone for minimizing cost functions in our models. But what exactly is it and why is it so important?<br><br>Let's start by dissecting the name. 'Gradient', in the simplest terms, measures the rate at which the output of a function changes at each point. It's like a compass for our algorithm, pointing the direction of the greatest rate of increase. Then comes 'Descent', indicating our goal of reaching the minimum value of the function. Imagine standing on a hill and wanting to get to the bottom - Gradient Descent is the GPS that guides us there!<br><br>So, how does this GPS guide us? The process starts with a random point on the function. We then move in the direction opposite to the gradient, nudging us closer to the local or global minimum. Here's where the 'learning rate' comes in - it's the step size that we take towards the minimum. Think of it as the speed of our descent. Too high a speed, and we risk overshooting our destination. Too slow, and our journey becomes painfully long. The algorithm continues these steps until it converges to the minimum point. <br><br>The beauty of Gradient Descent lies in its wide application. From Linear Regression and Logistic Regression to Neural Networks and Support Vector Machines, this versatile algorithm is at the heart of training various machine learning models. Moreover, it comes in three flavors: Batch Gradient Descent (using all data points for each update), Stochastic Gradient Descent (utilizing a single, random data point for each update), and Mini-Batch Gradient Descent (employing a small set of data points for each update). Thus, depending on the size of the dataset and computational efficiency, we can select the best-suited variant.<br><br>However, every hero has its Achilles heel. Gradient Descent can sometimes get stuck in local minima for non-convex error surfaces or can be sensitive to the initial point or learning rate. It may also stumble when feature scales are different. But fret not! Despite these limitations, the importance of Gradient Descent in machine learning is undisputed. It continues to be a vital tool in our arsenal and a stepping stone to understanding more complex optimization algorithms. <br><br>In conclusion, understanding Gradient Descent is akin to unlocking a fundamental secret of the universe of machine learning. It not only equips us with a robust optimization tool but also lays a solid foundation for grasping more advanced concepts in this fascinating field.<br><br></span>
This is not really a bad result for the first try, you can easily see the places it can go!
Using CrewAI with Local Agents
For those of us not keen on cloud dependencies or looking to cut costs, running models locally is a way to go. You can try different tasks with smaller models like Mistral and see how they stack up against GPT-4 or Claude in terms of output quality.
You just need to setup Ollama in your environment and create an instance of the Ollama model. You can then use it as Agent’s llm argument as shown in the example below:
<span id="83cf" data-selectable-paragraph=""><span>from</span> langchain.llms <span>import</span> Ollama<br>ollama_openhermes = Ollama(model=<span>"openhermes"</span>)<br><br><br>local_expert = Agent(<br> role=<span>'Local Expert at this city'</span>,<br> goal=<span>'Provide the BEST insights about the selected city'</span>,<br> backstory=<span>"""A knowledgeable local guide with extensive information<br> about the city, it's attractions and customs"""</span>,<br> tools=[<br> SearchTools.search_internet,<br> BrowserTools.scrape_and_summarize_website,<br> ],<br> llm=ollama_openhermes, <br> verbose=<span>True</span><br>)</span>
Points to Consider for Evaluation
There are very simple ways to evaluate the quality of the outputs before getting too much technical.
To begin with, you need to establish clear criteria that reflect your intended use cases. Are you looking for CrewAI to generate informative and engaging content based on current research trends? Then your test cases should revolve around accuracy, relevance, and readability.
You should compare the information gathered and synthesized by the CrewAI agents against reliable test cases that you are familiar with. For example, it’s essential to verify the factual correctness of the data scraped and incorporated into the content by an agent.
Next, you can assess how well the agent captures the essence of scraped content. This isn’t just about regurgitating facts; it’s about ensuring the content is meaningful and aligns with technical concepts and direction.
Lastly, you can check if the content not only technically accurate but also engaging and accessible to a broader audience. We want the prose to be crisp, clear, and free of jargon that could alienate non-expert readers.
On a separate note, if you are using GPT-4 API, be aware of the costs as depending on your set-up, you can quickly add up a few dollars. So keep an eye on response times, the number of API calls made, and the cost incurred per run. Think about the steps and mindful of inefficient operations.
A Personal Request to Our Valued Reader:
Each article we publish, every notebook we share, and all the resources we offer — they are part of our grand vision, a commitment to a world where everyone has skills and tools to put AI to work for themselves, driving positive change and innovation in their lives.
We pour our passion, expertise, and countless hours into creating content that we believe can make a difference in your journey.
But, here’s a surprising fact: Out of the thousands who benefit from our content, only a mere 1% choose to follow us on Medium.
Our dream is to see that number rise to 10%.
Your follow, clap, or comment isn’t just a click to us, it’s a sign that we’re on the right track, it’s your way of steering the ship, letting us know what you want more of.
So if you ever found value in our work, please take a moment to follow us on Medium, clap this article and leave a comment — it’s a small gesture, but it means the world to us and helps us tailor our content to your aspirations.
Thank you for stopping by, and being an integral part of our community. Together, we can shape the world.
Lastly, for those wanting to run models locally, experiment with different bases and versions such as mistralai/Mistral-7B-v0.1, NousResearch/Nous-Hermes-llama-2–7b, and cognitivecomputations/dolphin-2.2.1-mistral-7b to see what works better in your case.
Notable Examples
Here are some the notable examples that I came across the internet:
João Moura, creator of CrewAI building games:
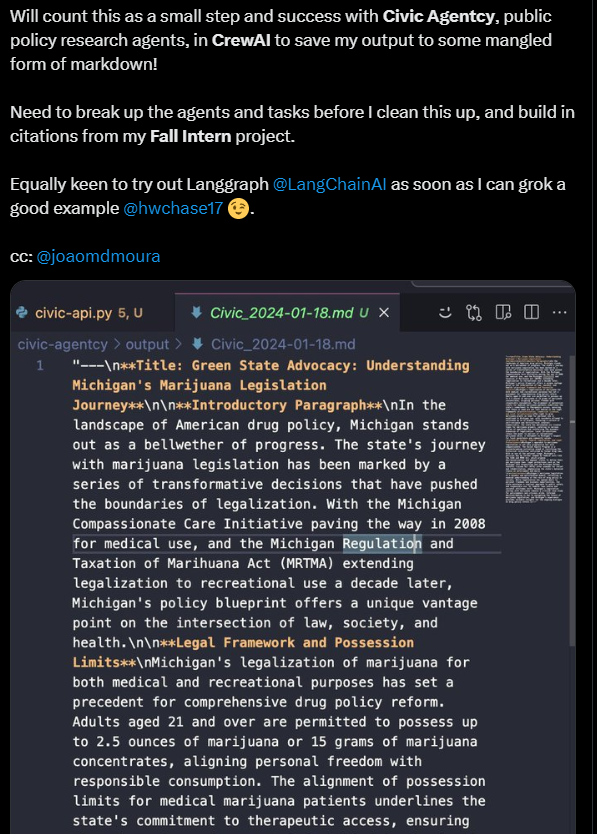
Civic Agentcy, public policy research agents:
H.P. Lovecraft, Mark Twain, and Carl Sandburg — to write a collaborative poem about America in 2023